MiniMax M2.7 on Mac: 10% Off and Cloud AI
MiniMax M2.7 explained: cloud AI for coding agents, benchmarks, Token Plan, 10% referral note, Ollama Cloud and local Mac alternatives.
The Raw Specs: Mixture of Experts with 230B Parameters
The official Hugging Face repository MiniMaxAI/MiniMax-M2.7 details a model that stands apart architecturally from standard dense models.
Under the hood, it operates as a large Mixture-of-Experts (MoE) model:
- Total Parameters: ~229 to 230 billion.
- Active Parameters per Token: ~10 billion.
- Context Window: 204,800 tokens (rounded to 200K in Ollama Cloud).
- Generation Speed: MiniMax lists roughly 60 output tokens/s for MiniMax-M2.7 and roughly 100 output tokens/s for the highspeed variant.
The MoE design means only a fraction of the model is active per token. The weights and runtime data still need to live somewhere. For normal Mac configurations this is not practical; even very large unified-memory Macs are research setups rather than comfortable daily targets for this model.
Here is the official benchmark overview published by the MiniMax team:
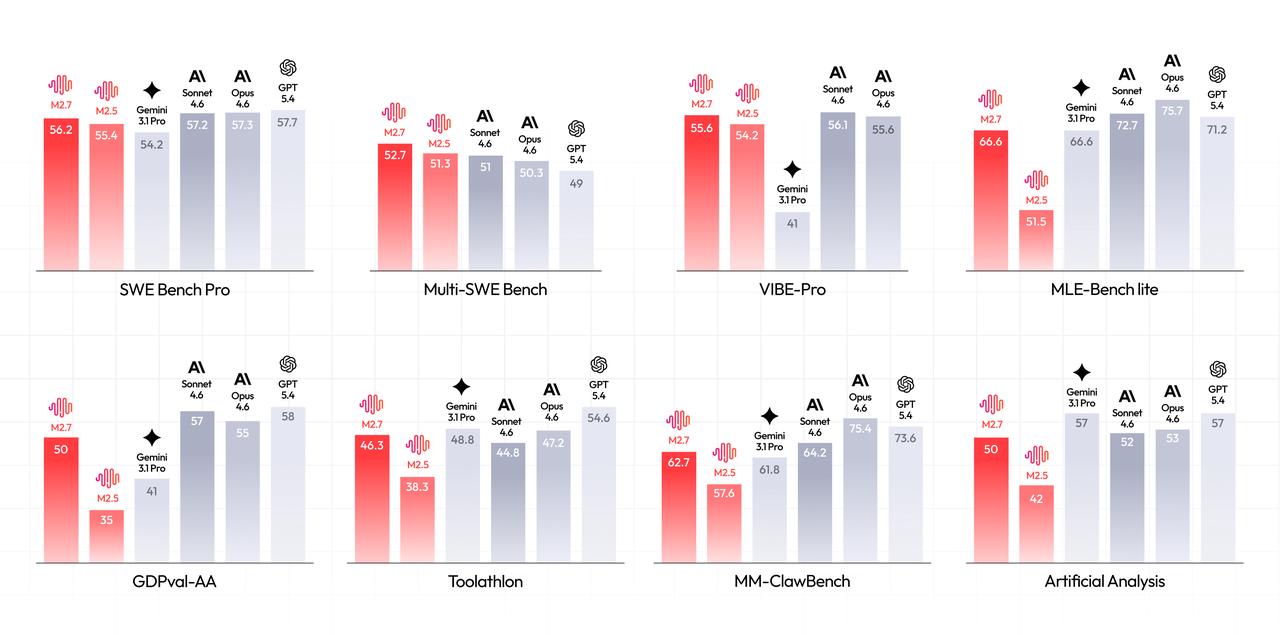 The official Hugging Face benchmark overview showcases where M2.7 sits in relation to other high-end models (Image Source: Hugging Face).
The official Hugging Face benchmark overview showcases where M2.7 sits in relation to other high-end models (Image Source: Hugging Face).
Model Self-Evolution: Real RL Focus
One important technical aspect is MiniMax’s focus on agentic training and reinforcement learning. The model card describes M2.7 as a model used inside internal training and optimization loops for coding and agent workflows.
MiniMax says the model could update memory structures, write programming skills for RL experiments and use test outcomes for optimization. These are MiniMax’s own claims.
The developers share two examples:
- Autonomous Optimization: An internal version of M2.7 autonomously optimized a programming scaffold over 100+ rounds. The model analyzed error logs, edited the code, ran the evaluations, and decided whether to keep or revert the changes. This achieved a 30% performance boost without any human intervention.
- Under 3-Minute Incident Recovery: Leveraging its deep understanding of system metrics, database traces, and log structures, MiniMax M2.7 is capable of making SRE-level decisions in live production environments, which successfully reduced recovery times to under three minutes on multiple occasions.
Here is how MiniMax visualizes the agent harness (the interaction between inference, tool use, and environment feedback):
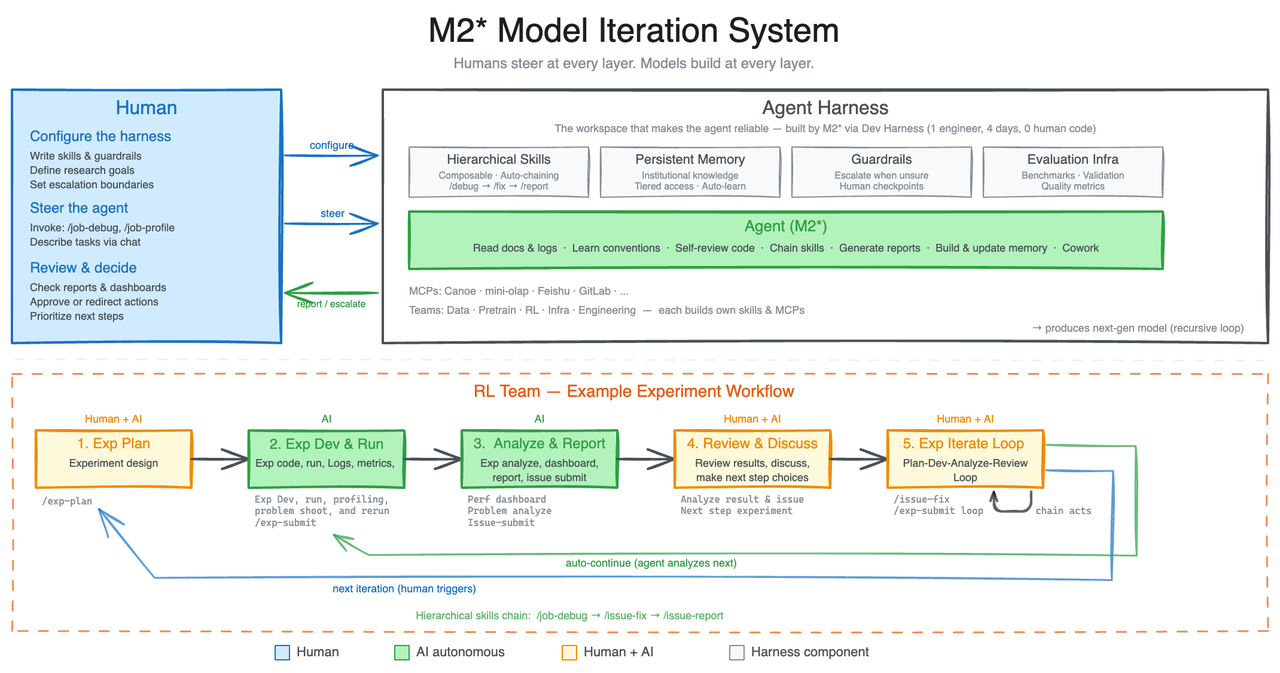 The inference and feedback loop in the agent harness, allowing the model to interact directly with its environment (Image Source: Hugging Face).
The inference and feedback loop in the agent harness, allowing the model to interact directly with its environment (Image Source: Hugging Face).
Benchmarks: Where Does M2.7 Stand?
The benchmark results from the Hugging Face model card are useful for positioning:
- Coding (SWE-Pro): MiniMax reports 56.22%.
- SWE Multilingual & Multi SWE Bench: MiniMax reports 76.5 and 52.7.
- MLE Bench Lite (ML Competitions): MiniMax reports a 66.6% medal rate across 22 ML competitions.
- GDPval-AA (Office ELO): MiniMax reports a score of 1495 for multi-step office-document tasks.
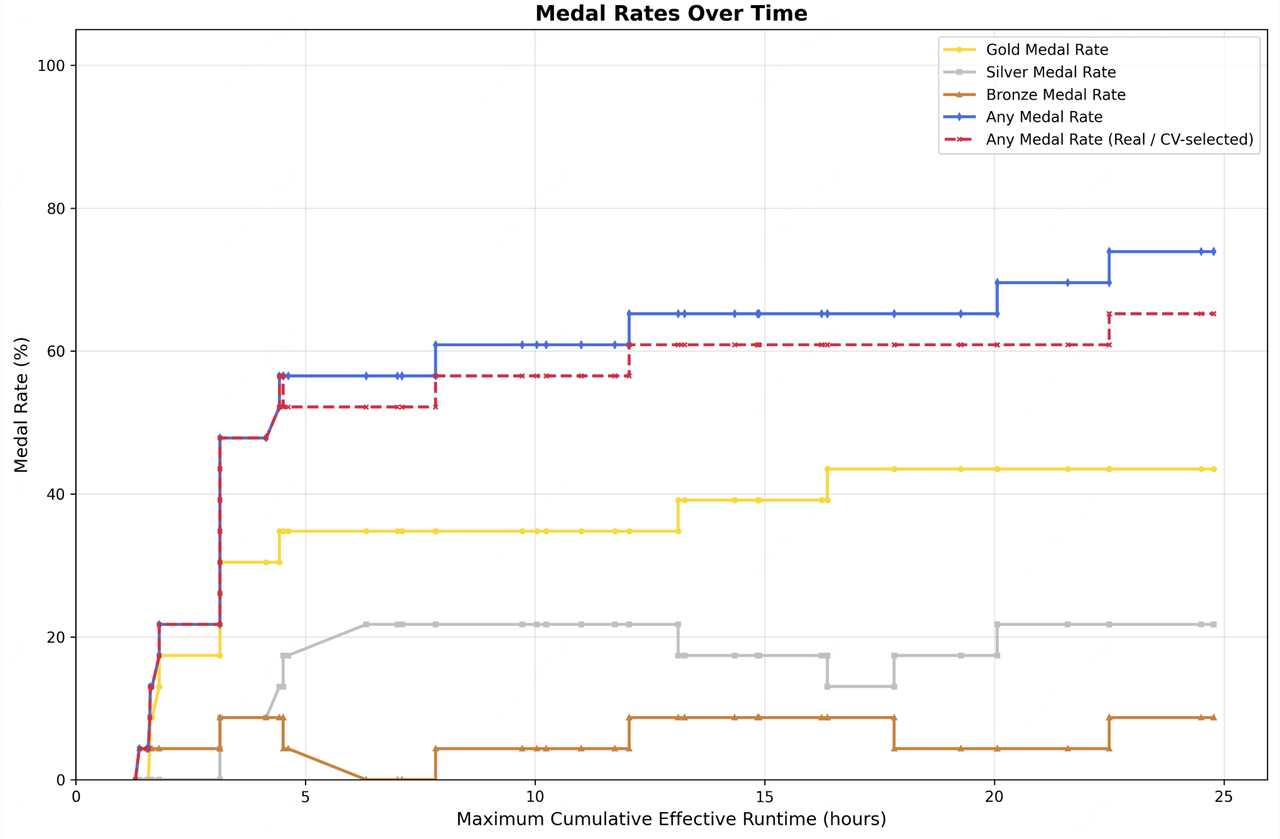 M2.7’s performance on the challenging MLE-Bench for machine learning agents (Image Source: Hugging Face).
M2.7’s performance on the challenging MLE-Bench for machine learning agents (Image Source: Hugging Face).
How to Use MiniMax M2.7 on the Mac
There are two primary ways to integrate the model into your Mac workflow. Since local Apple Silicon inference is impractical due to memory constraints, access is cloud-based:
1. Official API Access (Anthropic & OpenAI Compatible)
MiniMax exposes two API endpoints. If you want to use advanced features like Interleaved Thinking or Thinking Blocks, we recommend the Anthropic-compatible interface:
- Anthropic-Compatible Base URL:
https://api.minimax.io/anthropic - OpenAI-Compatible Base URL:
https://api.minimax.io/v1
2. Ollama Cloud Integration
Highly convenient: you can access the model directly via your terminal or inside tools like Open WebUI using your local Ollama command:
ollama run minimax-m2.7:cloudThe :cloud suffix is key: Ollama acts as the local client wrapper, while the computation is run in the licensed Ollama Cloud infrastructure.
3. For Server Setups (vLLM, SGLang, Transformers)
If you have access to a GPU cluster or suitable cloud server, you can download the weights directly and host them. MiniMax recommends inference frameworks like SGLang or vLLM.
Recommended inference parameters are:
temperature = 1.0
top_p = 0.95
top_k = 40Local Execution on Mac: What if You Have Enough RAM?
Since MiniMax M2.7 has been released as an open-weight model on Hugging Face, Mac users with large workstations will naturally ask a fair question: Can’t I just run this model locally if I own a Mac Studio with a very large amount of Unified Memory?
The honest answer is: Possible as an experiment on a high-memory Mac, but not a normal Mac recommendation.
This is due to two major barriers:
- The Memory Threshold: A 230-billion-parameter FP16 model takes roughly 460 GB just for weights. Even with aggressive 4-bit quantization, memory demand plus runtime overhead remains very high. A normal Mac mini, MacBook Air or MacBook Pro is out; even 128/192 GB Macs are not comfortable daily targets.
- The Software and Runtime Hurdle: Community quantizations and MLX/LM Studio paths now exist. A 3-bit build is roughly 112 GB for weights alone, so a Mac Studio with at least 128 GB of unified memory is a realistic floor once runtime, context and macOS overhead are included. This remains a specialist setup, not an ordinary Ollama workflow.
There is no reliable general Mac token/s number to cite because model format, quantization, context and runtime materially change performance. Cloud access remains the more realistic route for responsive agent loops.
Conclusion: Local loading can be interesting for research if the hardware, memory and software path fit. For productive editor use or long-running agent loops, MiniMax M2.7 on Mac is currently a cloud model.
Interactive Entertainment & OpenRoom Demo
MiniMax also shows M2.7 in interactive scenarios. The developers released OpenRoom, a Web GUI demo with AI interaction in a 2D scene. For Mac users, this is a product demo rather than a local runtime path.
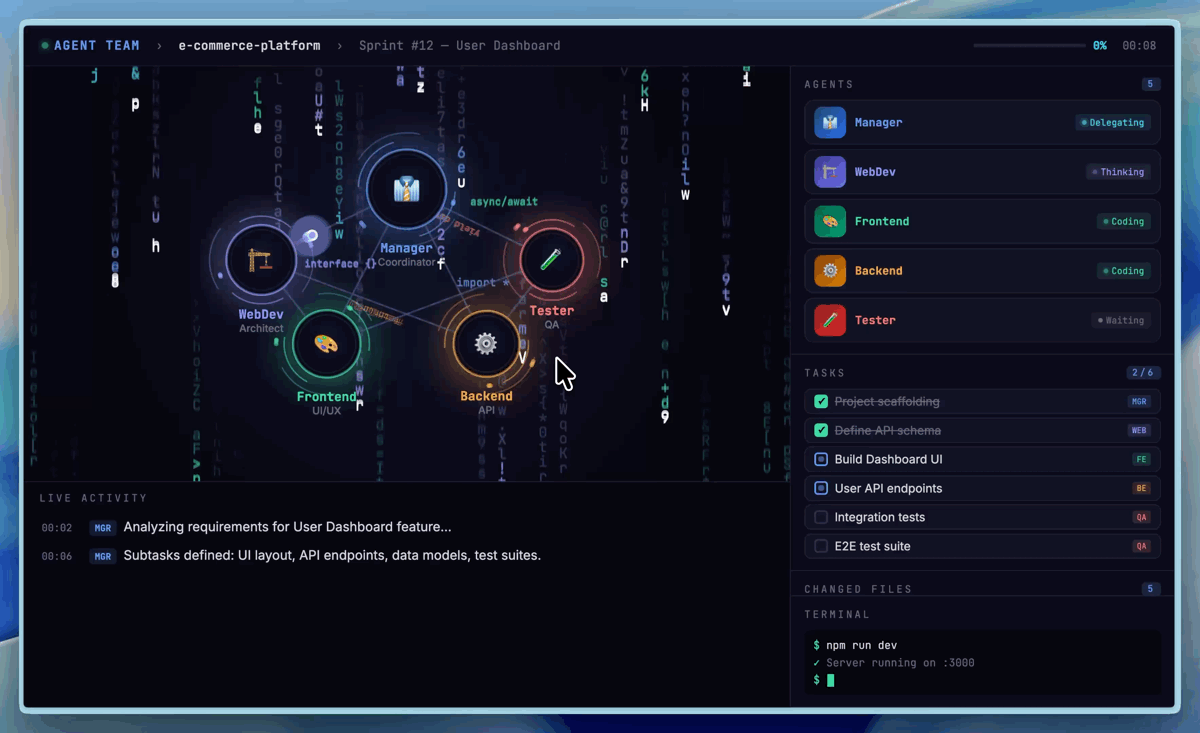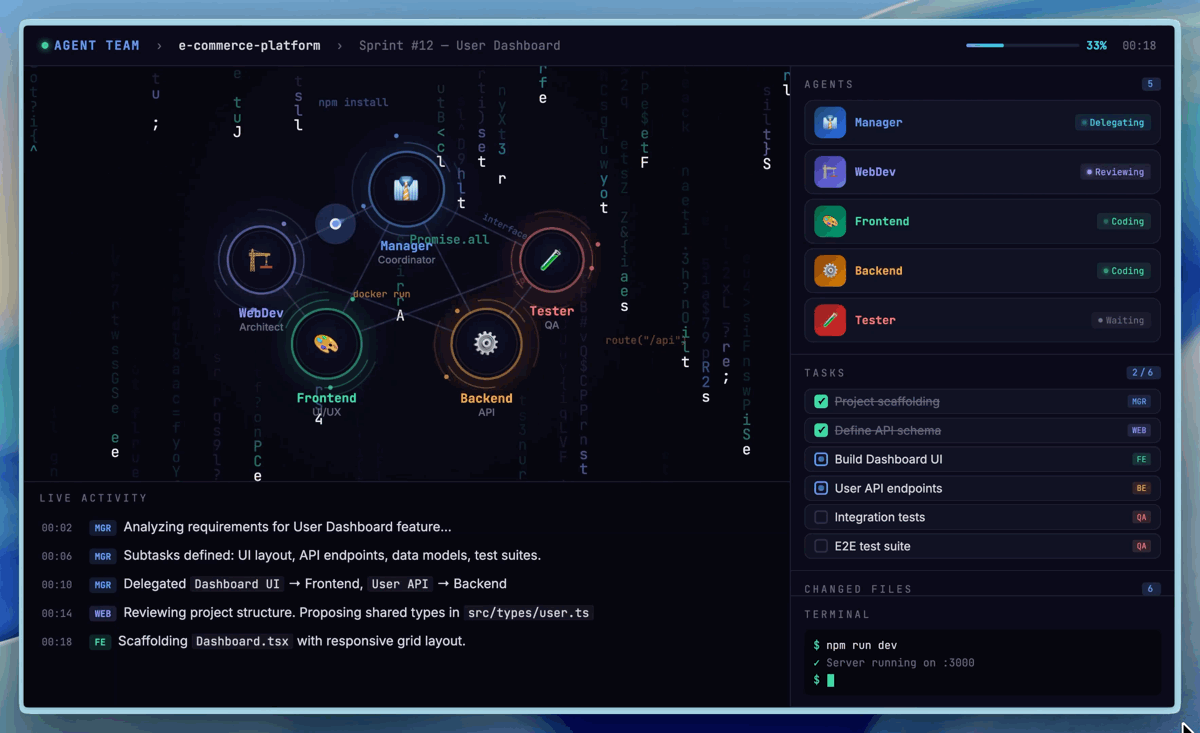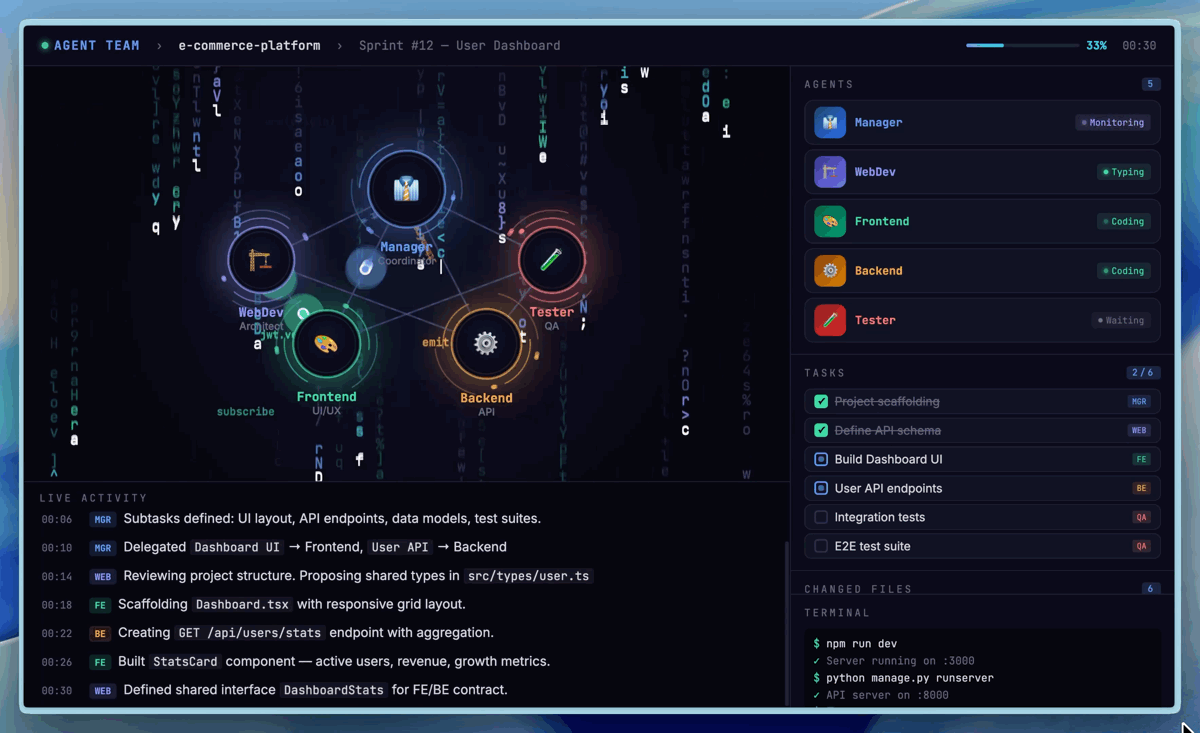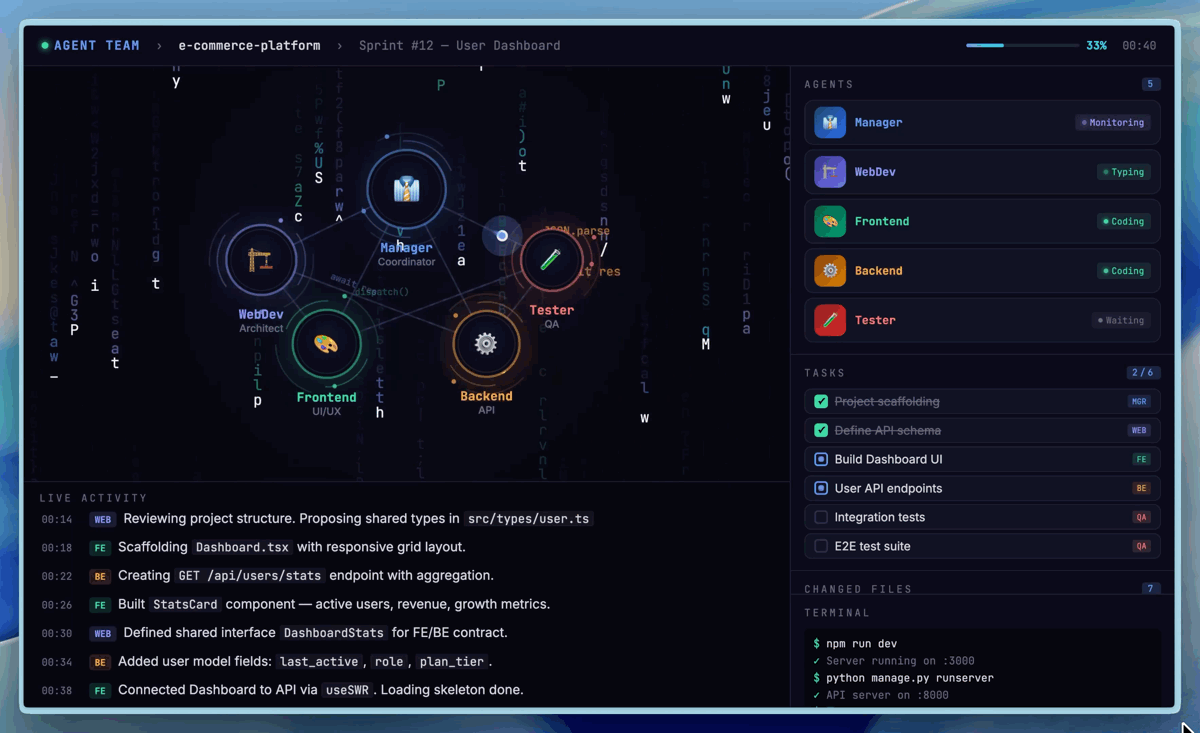 Visualization of native multi-agent collaboration (Agent Teams) in M2.7 (Image Source: Hugging Face).
Visualization of native multi-agent collaboration (Agent Teams) in M2.7 (Image Source: Hugging Face).
Token Plan: Pricing and Quotas
Using MiniMax via the API or the Open Platform requires a paid subscription called the “Token Plan.” Requests are counted within quotas that reset every 5 hours:
| Plan | Monthly price | M2.7 usage |
|---|---|---|
| Plus | $20 / month | rolling five-hour and weekly windows |
| Max | $50 / month | rolling five-hour and weekly windows |
| Ultra | $120 / month | rolling five-hour and weekly windows |
Current documentation describes rolling five-hour and weekly usage windows instead of fixed request counts. Legacy Starter and High-Speed tiers remain only for existing subscribers. Prices and quotas can change; the checkout is what matters.
The Referral Link
Ad / referral link: The MiniMax M2.7 page advertises a 10% discount for invited users. Open this MiniMax Token Plan link and check whether the discount appears at checkout. If you subscribe through it, I may receive API test credit. Important: the separate referral docs list an earlier event period, so the checkout display is what matters for discount, plan, renewal period and currency.
Local Alternatives for Your Mac
If you prefer not to send private codebases or sensitive files to external cloud APIs, local models are the better direction. They are only truly offline if your tooling, shared servers, plugins and web search are local or disabled too.
- Qwen 3.6 / Qwen-Coder variants: Good candidates for local coding workflows, depending on RAM, quantization and available model variant.
- Gemma 4 / Gemma variants: Sensible if you want a local all-round model with good Apple Silicon efficiency.
- Llama or Mistral variants: Practical for general assistant tasks when you want broad support in Ollama, LM Studio or llama.cpp.
Important Considerations Before Use (Checklist)
- No Offline Functionality: Even when running
minimax-m2.7:cloudinside Ollama, it will not work without an active internet connection. - Be Mindful of Privacy: Since inference occurs on remote cloud servers, keep confidential client code or proprietary data locally processed using Gemma or Qwen.
- Benchmarks Are Not Daily Guarantees: Excellence in SWE-Bench is a strong indicator, but real-world performance depends heavily on the unique context, setup, and prompts of your codebase.
Conclusion
MiniMax M2.7 remains relevant for agent, coding and office workflows, but it is no longer MiniMax’s newest text model: MiniMax M3 sits above it as of June 2026. On Mac, local M2.7 is a high-memory specialist project, Ollama labels its package as a cloud model, and sensitive data is better suited to genuinely local workflows with smaller models.
Sources and Date
Current as of: June 13, 2026. Prices, quotas, promotion periods and referral terms are subject to change. Always verify prices on the official MiniMax platform during checkout.
Frequently Asked Questions
Is MiniMax M2.7 a local Mac model?
No. For normal users, MiniMax M2.7 is a cloud/API model. Ollama also labels it as minimax-m2.7:cloud, which is not local open-weight inference on your Mac.
How large is the MiniMax M2.7 context window?
MiniMax lists MiniMax-M2.7 and MiniMax-M2.7-highspeed with a 204,800 token context window in the API docs. Ollama rounds this to 200K tokens in its cloud library.
What is the difference between MiniMax-M2.7 and MiniMax-M2.7-highspeed?
According to MiniMax, both use the same context window and should provide the same results. The standard variant is listed at roughly 60 output tokens per second, while the highspeed variant is listed at roughly 100 output tokens per second.
Is there really a 10 percent discount through the referral link?
The MiniMax M2.7 page advertises a 10 percent discount for invited users. The separate referral docs also list an earlier event period. In practice: open the link, check the checkout discount, then decide.