MiniMax M2.7 auf dem Mac: 10 % Rabatt und Cloud-KI
MiniMax M2.7 erklärt: Cloud-KI für Coding-Agenten, Benchmarks, Token Plan, 10-%-Referral-Hinweis, Ollama Cloud und lokale Mac-Alternativen.
Die nackten Zahlen: Mixture-of-Experts mit 230B Parametern
Die offizielle Hugging Face Repository MiniMaxAI/MiniMax-M2.7 zeigt ein Modell, das sich architektonisch von vielen gängigen Modellen unterscheidet.
Unter der Haube arbeitet ein großes MoE-Modell (Mixture of Experts):
- Gesamt-Parameter: ca. 229 bis 230 Milliarden.
- Aktive Parameter pro Token: ca. 10 Milliarden.
- Kontextfenster: 204.800 Tokens (in Ollama Cloud auf 200K gerundet).
- Ausgabegeschwindigkeit: MiniMax nennt für MiniMax-M2.7 ungefähr 60 Output-Tokens/s und für die highspeed-Variante ungefähr 100 Output-Tokens/s.
Das MoE-Design sorgt dafür, dass trotz der großen theoretischen Modellgröße pro Token nur ein Bruchteil berechnet wird. Trotzdem müssen die Gewichte und Runtime-Daten irgendwo liegen. Für normale Mac-Konfigurationen ist das nicht praktikabel; selbst sehr große Unified-Memory-Macs wären eher Forschungs- als Alltags-Setups.
Der Benchmark-Überblick von MiniMax:
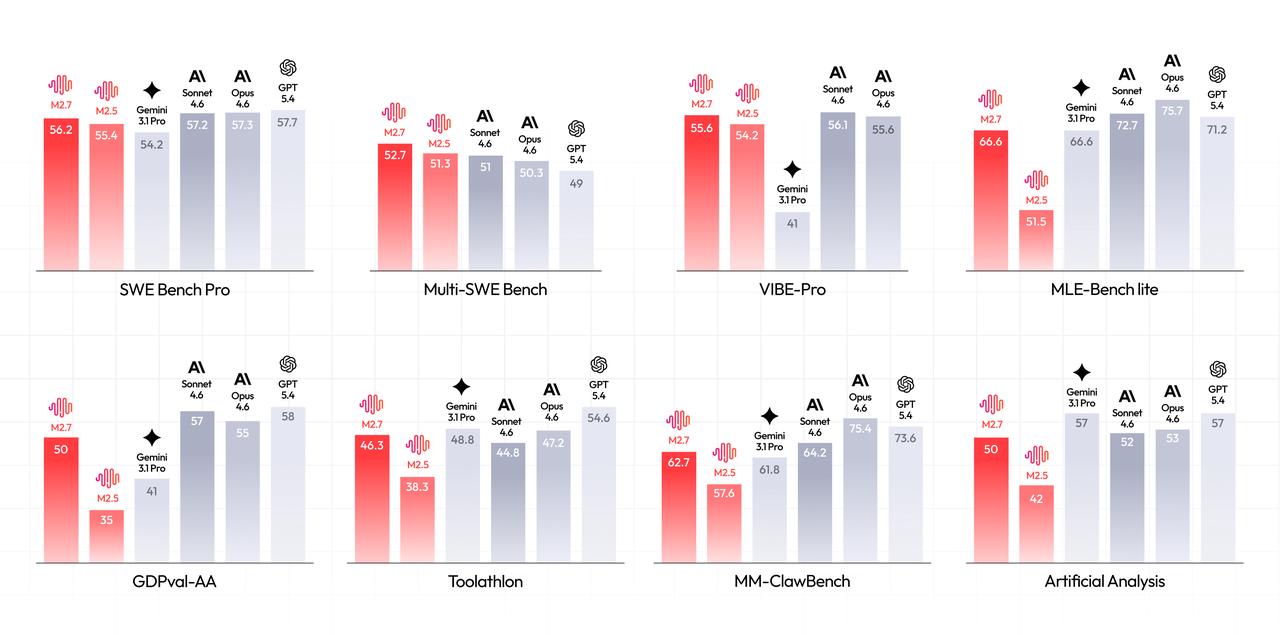 Benchmark-Übersicht von Hugging Face zeigt die Positionierung von M2.7 im Vergleich zu anderen High-End-Modellen (Bildquelle: Hugging Face).
Benchmark-Übersicht von Hugging Face zeigt die Positionierung von M2.7 im Vergleich zu anderen High-End-Modellen (Bildquelle: Hugging Face).
Modell-Selbstevolution: Kein Marketing-Hype, sondern RL-Fokus
Ein wichtiger technischer Aspekt ist MiniMax’ Fokus auf agentisches Training und Reinforcement Learning. Die Model Card beschreibt M2.7 als Modell, das in internen Trainings- und Optimierungsprozessen selbst Aufgaben für Coding- und Agenten-Workflows bearbeitet hat.
Was bedeutet das konkret? Laut MiniMax konnte das Modell in Experimenten Memory-Strukturen aktualisieren, Programmier-Skills für RL-Experimente schreiben und Testergebnisse zur Optimierung nutzen.
Die Entwickler beschreiben zwei Praxisbeispiele:
- Autonome Optimierung: Eine interne M2.7-Version optimierte ein Programmier-Scaffold über 100+ Runden hinweg vollständig autonom. Das Modell analysierte Fehler-Logs, korrigierte den Code, startete die Unit Tests selbstständig neu und entschied, ob Änderungen behalten oder verworfen werden. Das Ergebnis: Eine 30%ige Performance-Steigerung ohne menschliches Zutun.
- Incident Recovery unter 3 Minuten: Durch das starke Verständnis von Systemmetriken, Datenbank-Traces und Logs konnte MiniMax M2.7 in Live-Produktionsumgebungen SRE-Entscheidungen treffen und kritische Incident-Recovery-Zeiten auf unter drei Minuten senken.
Hier sieht man, wie MiniMax sich den typischen Agent-Harness (das Zusammenspiel aus Inferenz, Tools und Feedback-Loop) vorstellt:
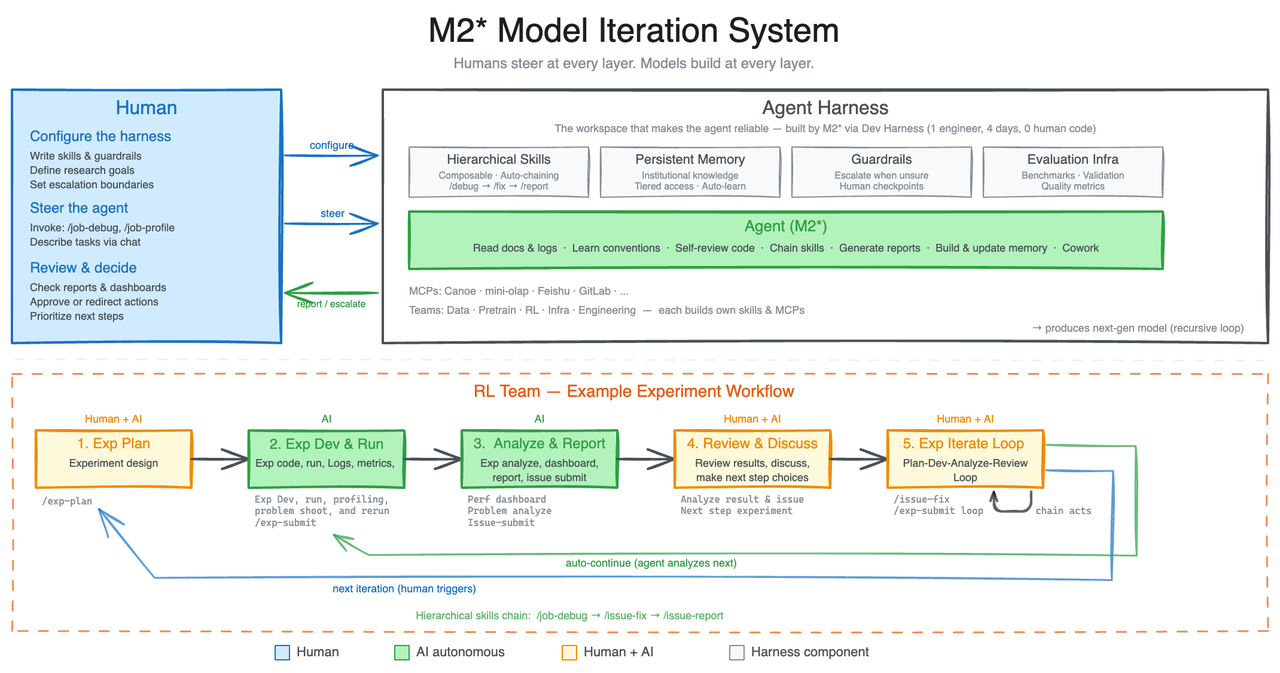 Der Inferenz- und Feedback-Loop im Agent-Harness, bei dem das Modell direkt mit seiner Umgebung interagiert (Bildquelle: Hugging Face).
Der Inferenz- und Feedback-Loop im Agent-Harness, bei dem das Modell direkt mit seiner Umgebung interagiert (Bildquelle: Hugging Face).
Benchmarks: Wo steht M2.7 im Vergleich?
Die Benchmark-Ergebnisse aus der Hugging-Face-Model-Card sind Anbieterwerte. Nützlich zur Einordnung:
- Coding (SWE-Pro): MiniMax meldet 56,22 %.
- SWE Multilingual & Multi SWE Bench: MiniMax meldet 76,5 beziehungsweise 52,7.
- MLE Bench Lite (ML-Competitions): MiniMax meldet eine 66,6 % Medal Rate über 22 ML-Wettbewerbe.
- GDPval-AA (Office-ELO): MiniMax meldet einen Score von 1495 für mehrstufige Office-Dokument-Aufgaben.
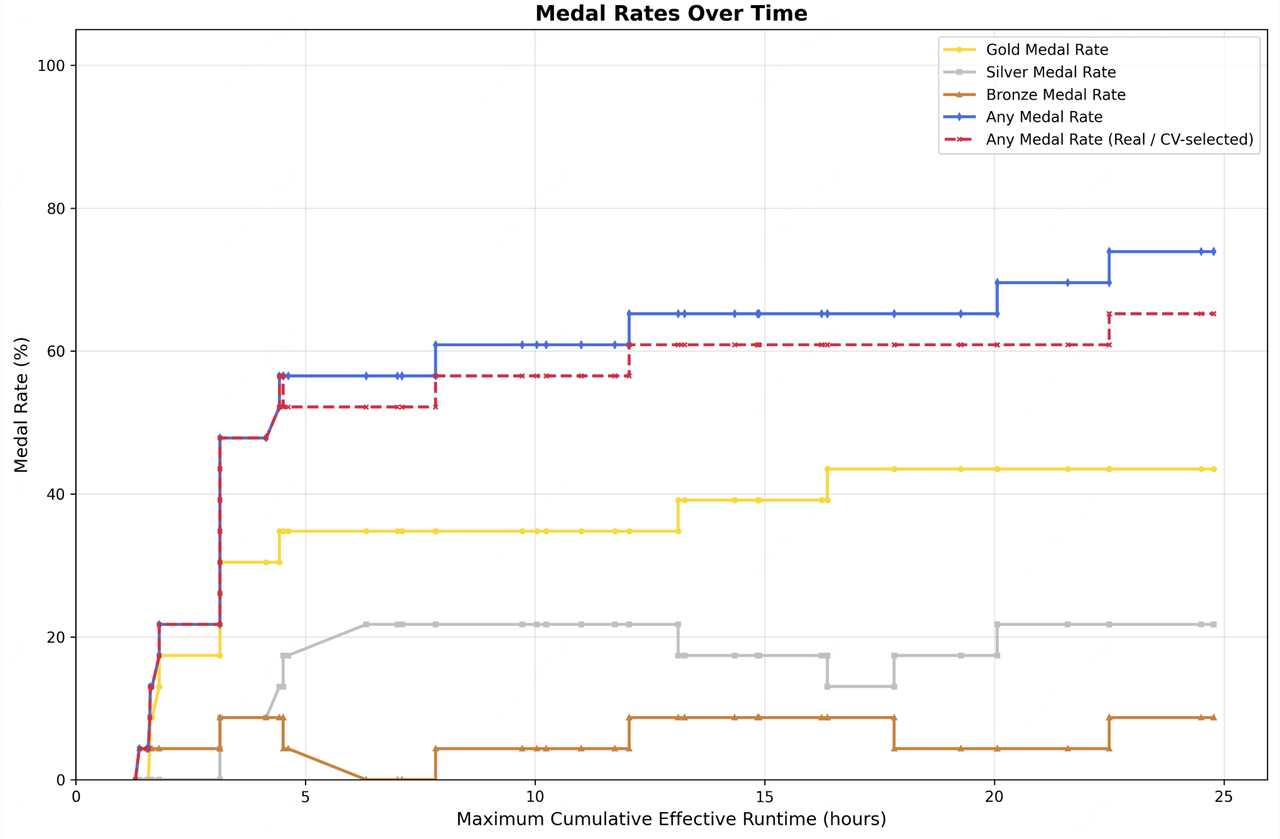 Die Leistung von M2.7 im anspruchsvollen MLE-Bench für ML-Agenten (Bildquelle: Hugging Face).
Die Leistung von M2.7 im anspruchsvollen MLE-Bench für ML-Agenten (Bildquelle: Hugging Face).
Wie nutzt man MiniMax M2.7 auf dem Mac?
Es gibt zwei Wege, das Modell in deinen Mac-Workflow einzubinden. Da eine lokale Ausführung auf dem eigenen Apple Silicon Chip im Alltag aus Speichergründen flachfällt, läuft der Zugriff primär über Cloud-Schnittstellen.
1. Der offizielle API-Zugriff (Anthropic- & OpenAI-kompatibel)
MiniMax bietet zwei APIs an. Wenn du fortgeschrittene Funktionen wie Interleaved Thinking oder Thinking Blocks nutzen willst, empfiehlt sich die Anthropic-kompatible Schnittstelle:
- Anthropic-kompatible Base URL:
https://api.minimax.io/anthropic - OpenAI-kompatible Base URL:
https://api.minimax.io/v1
2. Ollama Cloud Integration
Sehr elegant gelöst: Du kannst das Modell direkt in deinem Terminal oder in Tools wie Open WebUI über deine Ollama-Installation ansprechen:
ollama run minimax-m2.7:cloudDer Zusatz :cloud verrät es: Ollama dient hier nur als Client, die Berechnung läuft lizenziert in der Ollama Cloud Infrastruktur.
3. Für Server-Setups (vLLM, SGLang, Transformers)
Wer Zugriff auf einen GPU-Cluster oder ein passendes Cloud-Server-Setup hat, kann die Gewichte direkt herunterladen und hosten. MiniMax empfiehlt dafür Inferenz-Frameworks wie SGLang oder vLLM.
Die empfohlenen Inferenz-Parameter lauten:
temperature = 1.0
top_p = 0.95
top_k = 40Lokale Ausführung auf dem Mac: Geht das mit genug RAM?
Da MiniMax M2.7 als Open-Weight-Modell auf Hugging Face bereitgestellt wurde, stellt sich für Mac-Nutzer mit großen Workstations eine berechtigte Frage: Kann ich das Modell nicht lokal laufen lassen, wenn ich ein Mac Studio mit sehr viel Unified Memory besitze?
Die ehrliche Antwort lautet: Auf einem High-Memory-Mac als Experiment möglich, aber nicht als normale Mac-Empfehlung. Das liegt an zwei großen Barrieren:
- Die Speicherschwelle: Ein FP16-Modell mit 230 Milliarden Parametern belegt grob 460 GB nur für die Gewichte. Selbst mit starker 4-Bit-Quantisierung bleibt ein sehr hoher Speicherbedarf plus Runtime-Overhead. Ein normaler Mac mini, MacBook Air oder MacBook Pro ist damit raus; selbst 128/192-GB-Macs wären keine komfortablen Alltagsziele.
- Die Software- und Kernel-Hürde: Für M2.7 existieren inzwischen Community-Quantisierungen und MLX-/LM-Studio-Pfade. Eine 3-Bit-Quantisierung liegt grob bei 112 GB nur für die Gewichte; für Runtime, Kontext und macOS ist deshalb ein Mac Studio mit mindestens 128 GB Unified Memory die realistische Untergrenze. Das bleibt ein Spezial-Setup und kein Ollama-Einstieg für normale Macs.
Für konkrete Mac-Token/s gibt es keine belastbare allgemeine Zahl; Modellformat, Quantisierung, Kontext und Runtime verändern das Ergebnis stark. Für flüssige Agenten-Loops ist der Cloud-Zugriff meist realistischer.
Fazit: Für Forschung und Experimente kann lokales Laden interessant sein, wenn Hardware, Speicher und Softwarepfad passen. Für produktives Coding im Editor oder längere Agenten-Loops ist MiniMax M2.7 auf dem Mac derzeit ein Cloud-Modell.
Unterhaltung & die OpenRoom-Demo
MiniMax zeigt M2.7 auch in interaktiven Szenarien. Die Entwickler haben OpenRoom veröffentlicht, eine Web-GUI-Demo mit KI-Interaktion in einer 2D-Szene. Das ist für Mac-Nutzer eher eine Produktdemo als ein lokaler Laufzeitpfad.
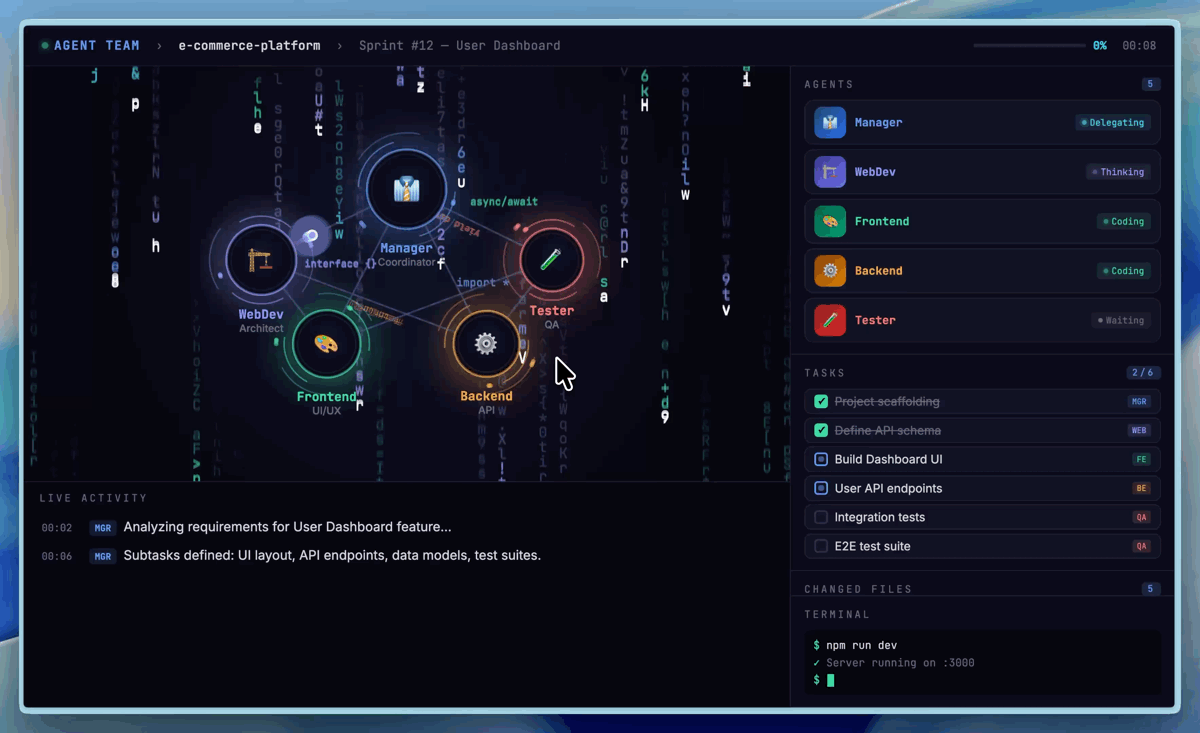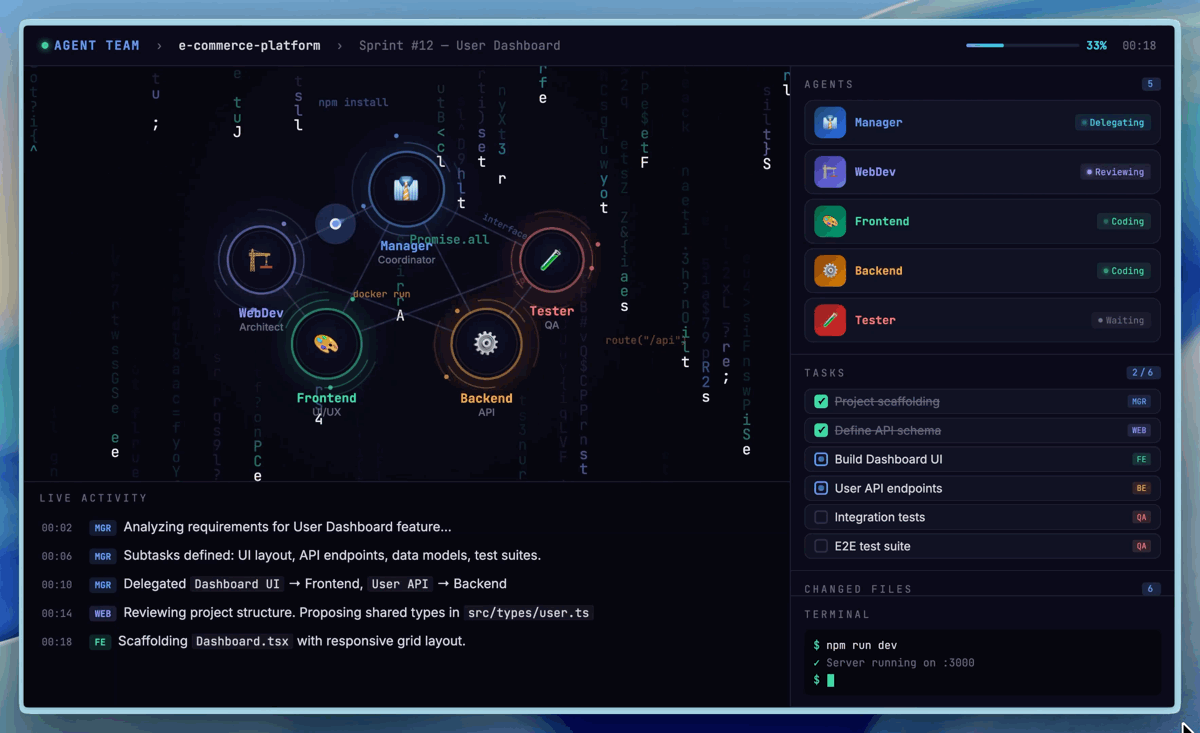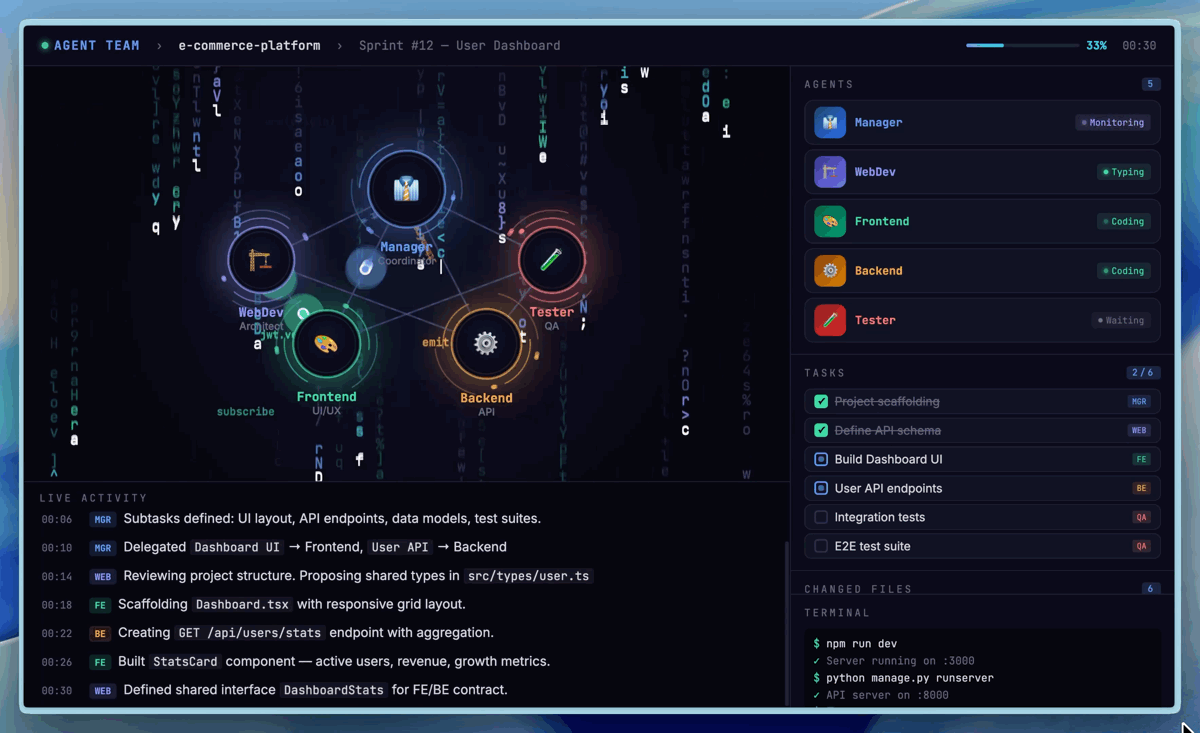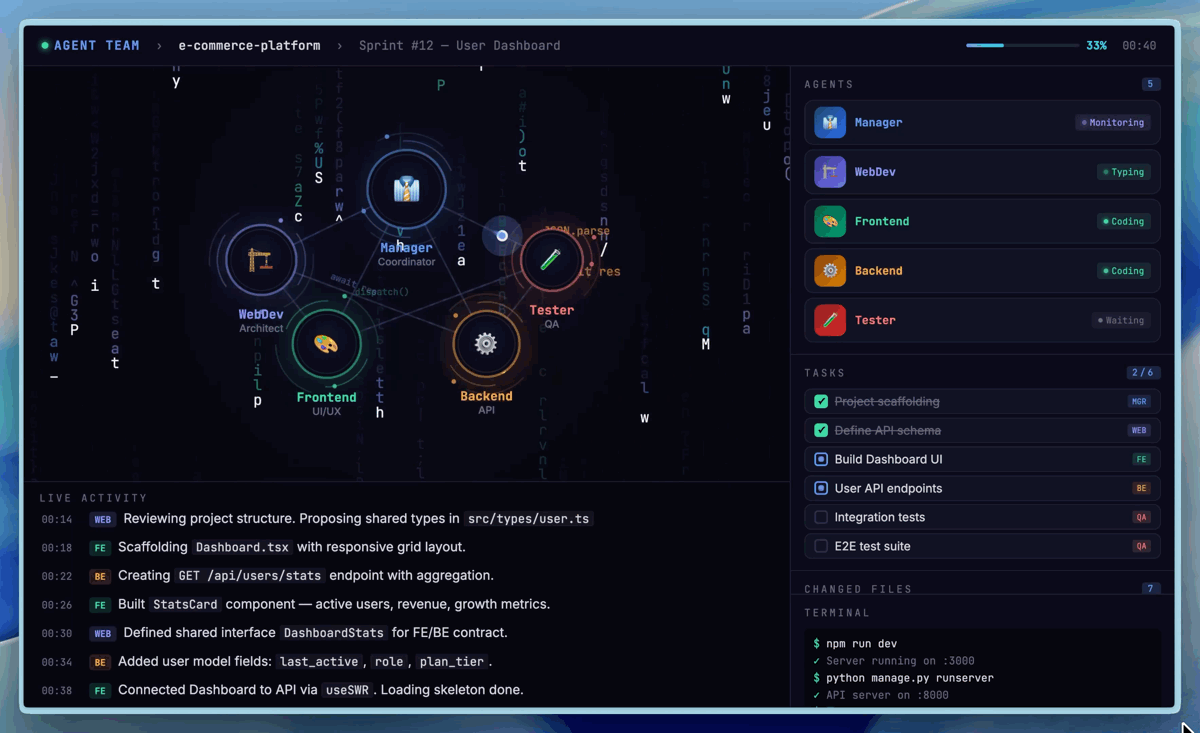 Visualisierung von nativen Multi-Agent-Teams (Agent Teams) in M2.7 (Bildquelle: Hugging Face).
Visualisierung von nativen Multi-Agent-Teams (Agent Teams) in M2.7 (Bildquelle: Hugging Face).
Token Plan: Preise und Quoten
Wenn du MiniMax über die API oder die Open Platform nutzen willst, kaufst du ein monatliches Abo (den „Token Plan“). Das Modell M2.7 wird dabei in Request-Quoten abgerechnet, die sich alle 5 Stunden zurücksetzen:
| Plan | Preis monatlich | M2.7-Nutzung |
|---|---|---|
| Plus | $20 / Monat | 5-Stunden- und Wochenfenster |
| Max | $50 / Monat | 5-Stunden- und Wochenfenster |
| Ultra | $120 / Monat | 5-Stunden- und Wochenfenster |
Die aktuelle Doku beschreibt Nutzung über rollierende 5-Stunden- und Wochenfenster statt fester Request-Zahlen. Alte Starter- und High-Speed-Tarife bleiben nur für bestehende Abonnenten erhalten. Preise, Quoten und Promotion-Bedingungen können sich ändern; entscheidend ist die Anzeige im MiniMax-Checkout.
Anzeige / Empfehlungs-Link: Die MiniMax-M2.7-Seite bewirbt einen 10-%-Discount für eingeladene Nutzer. Öffne dafür diesen MiniMax-Token-Plan-Link und prüfe im Checkout, ob der Rabatt angezeigt wird. Wenn du darüber abschließt, kann ich ein API-Testguthaben erhalten. Wichtig: Die separate Referral-Doku nennt einen früheren Event-Zeitraum; deshalb zählt vor dem Kauf nur die Checkout-Anzeige für Rabatt, Plan, Laufzeit und Währung.
Lokale Alternativen für deinen Mac
Wenn du private Codebases, Protokolle oder Dokumente nicht an eine Cloud-API senden willst, sind lokale Modelle die bessere Richtung. Wichtig ist: Sie sind nur dann wirklich offline, wenn du Tooling, Server-Freigaben, Plugins und Websuche ebenfalls lokal beziehungsweise deaktiviert hältst.
- Qwen 3.6 / Qwen-Coder-Varianten: Gute Kandidaten für lokale Coding-Workflows, abhängig von RAM, Quantisierung und verfügbarer Modellvariante.
- Gemma 4 / Gemma-Varianten: Sinnvoll, wenn du ein lokales Allround-Modell mit guter Effizienz auf Apple Silicon suchst.
- Llama- oder Mistral-Varianten: Praktisch für allgemeine Assistenzaufgaben, wenn du breite Tool-Unterstützung in Ollama, LM Studio oder llama.cpp brauchst.
Für die meisten lokalen Workflows sind kleinere Modelle praktikabler. MiniMax M2.7 ist eine Cloud-Option oder ein Spezialprojekt für High-Memory-Macs, aber kein lokales Arbeitsmodell für einen normalen Mac.
Wichtige Punkte vor der Nutzung (Checkliste)
- Keine Offline-Nutzung: Auch wenn du
minimax-m2.7:cloudüber Ollama aufrufst – ohne aktive Internetverbindung läuft nichts. - Datenschutz im Auge behalten: Da es sich um Inferenz auf externen Servern handelt, solltest du sensible Kundendaten oder geheimen Quellcode lieber lokal mit Gemma oder Qwen verarbeiten.
- Nur weil M2.7 im SWE-Bench glänzt, heißt das nicht, dass es jede Code-Struktur in deinem Projekt versteht. Teste das Modell kritisch für deine eigenen Workflows.
Fazit
MiniMax M2.7 bleibt ein relevantes Cloud-Modell für Agenten-, Coding- und Office-Workflows, ist aber nicht mehr MiniMax’ neuestes Textmodell: Seit Juni 2026 steht MiniMax M3 darüber. Für Mac-Nutzer bleibt die Einordnung nüchtern: lokal ist M2.7 nur auf High-Memory-Systemen ein Spezialprojekt, über Ollama ist es als Cloud-Modell gekennzeichnet, und sensible Daten gehören eher in echte lokale Workflows mit kleineren Modellen.
Quellen und Stand
Stand: 13. Juni 2026. Preise, Quoten, Promotion-Zeiträume und Referral-Bedingungen können sich ändern. Prüfe vor dem Kauf immer die offizielle MiniMax-Seite und den Checkout.
Häufig gestellte Fragen
Ist MiniMax M2.7 ein lokales Mac-Modell?
Nein. MiniMax M2.7 ist für normale Nutzer ein Cloud-/API-Modell. Auch die Ollama-Variante ist als minimax-m2.7:cloud gekennzeichnet und damit keine lokale Open-Weight-Inferenz auf deinem Mac.
Wie groß ist das Kontextfenster von MiniMax M2.7?
MiniMax nennt in den API-Docs für MiniMax-M2.7 und MiniMax-M2.7-highspeed ein Kontextfenster von 204.800 Tokens. Ollama rundet das in der Cloud-Library auf 200K Tokens.
Was ist der Unterschied zwischen MiniMax-M2.7 und MiniMax-M2.7-highspeed?
Laut MiniMax haben beide dasselbe Kontextfenster und sollen dieselben Ergebnisse liefern. Die normale Variante wird mit ungefähr 60 Output-Tokens pro Sekunde beschrieben, die Highspeed-Variante mit ungefähr 100 Output-Tokens pro Sekunde.
Gibt es wirklich 10 Prozent Rabatt über den Referral-Link?
Die MiniMax-M2.7-Seite bewirbt einen 10-Prozent-Discount für eingeladene Nutzer. Die Referral-Doku nennt zugleich einen früheren Event-Zeitraum. Deshalb gilt praktisch: Link öffnen, Rabatt im Checkout prüfen, erst dann kaufen.